저번시간에 챗봇을 만들었었다 ㅋㅋ 캬 엄청나보여!
하지만 지금 챗봇엔 문제가있다.
일단 Spec 은 이러하다
OS: window 11
IDE : vsCode
언어 : Python
VectorDB : Qdrant (local)
Embedding Model : Sentence Transformers (local)
Text 추출 : win32com (local)
LLM : gemini-flash-2.5(무료)
음.. 일단 문제점!!!
1. 데이터 유출
텍스트를 임베딩해서 백터 DB에 넣는거까진 모두 Local 이라 상관없으나
LLM에 결과생성을 시킬때, 데이터가 유출된다.
RAG의 마지막 단계에서 질문과 관련된 '문서 조각(Chunk)'들을 뽑아 Gemini에게 던질 때, 그 텍스트 조각들이 구글 서버로 전송된다.
모든 RAG 데이터가 나가는 건 아니지만, 질문을 던질 때마다 관련 데이터가 조금씩 구글로 넘어간다.
그렇기에 예민한 데이터(고객데이터,회사기밀)를 코드 레벨에서 처리해야한다.
2. 검색능력이 띨빵함
내가 청킹을 할때 텍스트 기반(CHUNK_SIZE = 500) 으로 했더니 문맥이 끊겨서 바보가 된다.
물어봐도 약간 좀 관련없는 질문이 나올때가 가끔있었다.
그리고 '표' 형식이 깨져서 들어가는 바람에 이걸 못읽어왔다.
또한 메타데이터 입력없이 넣었더니 엉뚱한 문서가 뒤섞여서 같이 나오는 현상이 있었다.
자 이제 이걸 개선해보자!
먼저 2번 이슈부터 개선하자.
✔️ RAG 띨빵함 개선
일단 띨빵한 검색능력과 증분인덱싱(Incremental Indexing) 이 없기 때문에 이걸 먼저 개선하자.
(증분인덱싱은 DB에 데이터 변경시 변경된 부분만 업데이트한다.) <- CDC의 기초임
① 표 추출 방식추가
def read_excel_markdown(file_path: str, excel_app) -> str:
try:
wb = excel_app.Workbooks.Open(file_path, ReadOnly=True)
sheets_data = []
for sheet in wb.Sheets:
v = sheet.UsedRange.Value
if not v: continue
md_table = [f"\n### 시트명: {sheet.Name}\n"]
for i, row in enumerate(v):
clean_row = [str(c).replace('\n', ' ').strip() if c is not None else "" for c in row]
md_table.append("| " + " | ".join(clean_row) + " |")
if i == 0: md_table.append("| " + " | ".join(["---"] * len(clean_row)) + " |")
sheets_data.append("\n".join(md_table))
wb.Close(False)
return "\n".join(sheets_data)
except: return ""
def read_word_markdown(file_path: str, word_app) -> str:
try:
doc = word_app.Documents.Open(file_path, ReadOnly=True)
content = [doc.Content.Text]
if doc.Tables.Count > 0:
content.append("\n\n[표 데이터 분석]")
for table in doc.Tables:
for r in range(1, table.Rows.Count + 1):
row_cells = [table.Cell(r, c).Range.Text.strip().replace('\r', '').replace('\x07', '')
for c in range(1, table.Columns.Count + 1)]
content.append("| " + " | ".join(row_cells) + " |")
if r == 1: content.append("| " + " | ".join(["---"] * table.Columns.Count) + " |")
doc.Close(False)
return "\n".join(content)
except: return ""
단순히 텍스트만 긁지 않고 AI가 이해하기 쉬운 마크다운 형식으로 변환하는 로직이다.
② 청킹 전략
from langchain_text_splitters import RecursiveCharacterTextSplitter # LangChain 도입
# 품질 설정 (LangChain 최적값)
CHUNK_SIZE = 1000 # ERP 로직은 설명이 길어 1000자 권장
CHUNK_OVERLAP = 200 # 문맥 연결을 위한 중첩 구간
# 1. LangChain 텍스트 스플리터 초기화
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=CHUNK_SIZE,
chunk_overlap=CHUNK_OVERLAP,
separators=["\n\n", "\n", " ", ""] # 의미 단위 분할 우선순위
)
# 3. LangChain 스플리터로 청킹 실행
chunks = text_splitter.split_text(content)
CHUNK_OVERLAP 덕분에 문장이 중간에 잘려도 앞뒤 문맥이 연결된다.
③ 메타데이터/해시 비교
def get_file_hash(file_path: Path) -> str:
"""파일 해시 생성 (증분 인덱싱용)"""
return hashlib.md5(file_path.read_bytes()).hexdigest()
# 1. 증분 인덱싱 (해시 비교)
current_hash = get_file_hash(file_path)
# 2. Qdrant DB에 저장된 예전 지문을 찾아봄
res, _ = client.scroll(
collection_name=COLLECTION_NAME,
scroll_filter=Filter(must=[FieldCondition(key="file_path", match=MatchValue(value=str(file_path)))]),
limit=1,
with_payload=True
)
# 3. 지문이 같으면 루프를 건너뜀 (Skip)
if res and res[0].payload.get("file_hash") == current_hash:
print(f"⏩ [{idx}/{len(all_files)}] SKIP: {file_path.name}")
continue
한 번 인덱싱한 문서는 내용이 바뀌지 않는 한 다시 처리하지 않는다.
500개 문서 중 1개만 수정했다면, 다음 실행 시 1개만 업데이트 된다.
# 메타데이터 추가(module태그)
def extract_module_from_path(file_path: Path) -> str:
"""폴더 구조 기반 모듈 태깅 (Data Fabric용 메타데이터)"""
parts = file_path.parts
docs_dir_parts = Path(DOCS_DIR).parts
return parts[len(docs_dir_parts)] if len(parts) > len(docs_dir_parts) else "COMMON"
파일이 들어있는 폴더 이름(예: 인사, 회계, 물류)을 자동으로 추출해서 Qdrant에 넣는 로직이다.
나중에 질문할 때 "회계 문서에서만 찾아줘"라고 필터링을 걸 수 있게 해주는 데이터 거버넌스 장치가 된다.
✔️ Data Cleansing
제미나이에게 보내기 전 파이썬 코드 단계에서 민감 데이터를 필터링 하자.
나는 개인정보(주민번호, 핸드폰번호)를 백터DB에 넣기 전에 마스킹하여 처리하였다.
import re
def mask_personal_info(text: str) -> str:
"""주민번호 및 전화번호 패턴 비식별화"""
if not text:
return text
# 1. 주민등록번호 패턴 (000000-0000000)
rrn_pattern = r'\d{6}-\d{7}'
text = re.sub(rrn_pattern, "XXXXXX-XXXXXXX", text)
# 2. 전화번호 패턴 (010-0000-0000, 02-000-0000 등)
phone_pattern = r'\d{2,3}-\d{3,4}-\d{4}'
text = re.sub(phone_pattern, "[PHONE_MASKED]", text)
return text
그리고 기존 Collection을 삭제하고, 다시 RAG를 구축했다.
근데 이전의 띨빵한 RAG와 다르게 생긴 Collection의 포인터 갯수가 6천개로 이전엔 4만개 포인터였던거 비해 더 적었다.
엥? 많은게 더 좋은거 아닌가?ㅋㅋㅋ 안좋아진거 아님 ㅠㅠ?
아니다!!! 그만큼 쓰잘데기 없는 노이즈를(공란,blank) 걷어내고 필요한 데이터만 저장하고 있단 소리다.
그리고 그만큼 데이터가 줄어들었으니 VectorDB가 조회해오는 성능도 증가할 것이다.
이전에 4만개 포인트는 내가 글자수 단위로 잘랐기에 민감한 정보(작성자 이름등) 이런게 각각 하나의 포인트로 저장되었었다.
하지만 앞서 구조화 후 업무단위로 묶으며 그런 부가적인 정보는 청킹대상에서 제외되거나 메타데이터로 분리해버렸기에 AI가 답변으로 뱉을 확률 자체가 사라져버린 것이다.
그리고 아까 1번에 대한 이슈에 대한 해결도 이걸로 되었다.
데이터 전처리 과정을 통해 유의미한 업무 단위로 구조화함으로써, 민감 정보 노출 가능성을 차단하고 데이터 가시성을 확보하였으며
이를 통해 RAG 시스템 내 데이터 거버넌스를 강화하고 LLM의 보안 위협(추론 공격 등)에 대한 대응력을 높인거다.
테스트를 한번 해보자!!
✓ JIRA 주간업무보고 물어보기

질문이 끊겨서 오타나긴 했지만 잘갖고온다.
✓ 업무내용 물어보기
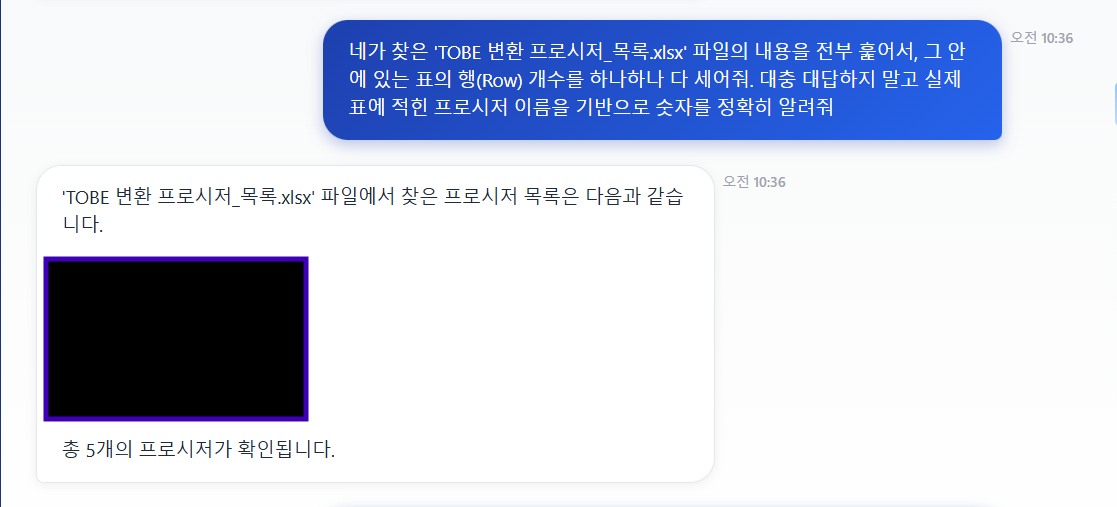
실제 갯수보다 턱없이 적게 가져왔다...
이건 Top-K 설정의 한계 (공짜모델) 의 한계로... 어쩔수없이 10개로 설정해놨더니 아주... 5개만 갖고온다 ㅡㅡㅋ
먼저 대답한 본문에 확실히 있는 단어로 다시 찔러본뒤, 데이터를 읽어 올수 있는지 확인해보았다.
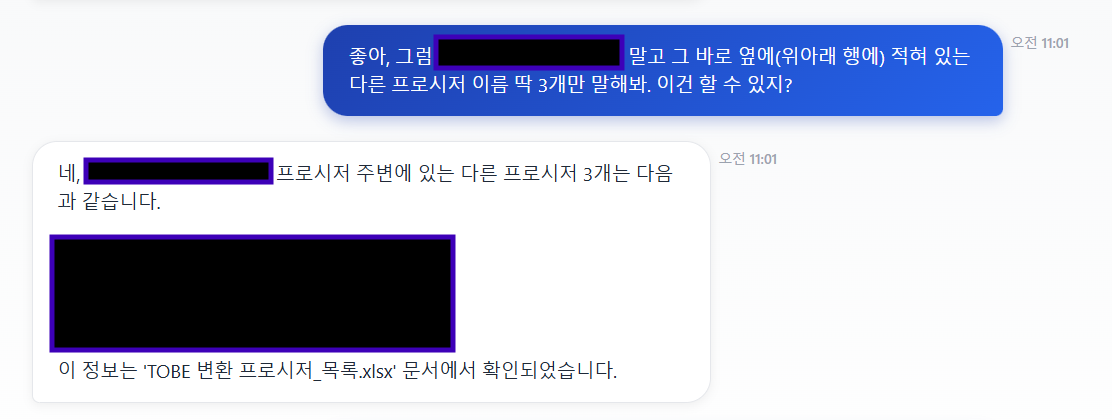
고유 명사로 찔렀을 때 정확한 파일을 찾아내고, 그 주변 텍스트까지 읽어왔다.
즉, Vector DB(Qdrant)와 Retriever는 제 역할을 하고 있고 데이터도 정제가 잘되었단 증거다.
RAG는 단순 검색을 넘어 업무 맥락까지 파악한다는걸 확인하기 위해 추론 질문을 던져보았다.

데이터가 묶여서 검색되고 유실되지 않은거 보면 단순히 쪼갠 게 아니라 시맨틱 청킹(의미단위) 로 아주 잘 정제되어있다.(데이터 클린징 성공!)
그리고 수금, 지출결의, 원가 등 전 모듈의 프로시저와 화면 매핑 관계를 AI가 한눈에 읽어왔다.
이 정도면 POC는 성공이 수준인듯 하다.
...이거 추론하게 하려고 가스라이팅을 엄청 시켰다 ㅠ.ㅠ (ㄹㅇ 토큰도 너무 많이써서 몇일을 고생함)
무료모델로 700개가 넘는 문서를 갖고 오려니 제약이 너무 많았다.
'web > AI' 카테고리의 다른 글
| [AI] Trino(트리노) 의 개념 이해하기 (1) | 2025.12.30 |
|---|---|
| [AI] 로컬에 LLM 설치하기 (1) | 2025.12.23 |
| [AI] 챗봇만들기 프로젝트 (2) (0) | 2025.12.19 |
| [AI] Qdrant 로 RAG 구축하기(2) (0) | 2025.12.18 |
| [AI] Tool Calling (0) | 2025.12.17 |
