요즈음 남편이 본인 편하고자(?) 가계부 앱을 만들고 있는데 거기에 뭐 도움될만한게 없을까 하다가...
가계부를 위한 DataLake를 구축해주기로 하였다.
처음부터 거창하게 시작하지 않고 간단하게 Poc부터 먼저 해보고 차차 확장해나갈 예정이다.
우선 같이 쓴 가계부 데이터 3년치가 있기에 이걸 토대로 한번 시작해보려 한다.
일단 간단하게 3년치의 RAW 데이터를 의미있는 데이터로 변환하는 데이터파이프 라인을 구축해보자.
[개발환경]
- AWS S3
- AWS Lambda
- Python
- Pandas
✔️ 일단 S3 버킷부터 생성하자.
1. AWS Console 접속
https://aws.amazon.com/ko/console/
AWS 리소스 관리 — AWS 관리 콘솔 — AWS
AWS Management 콘솔을 사용하여 웹 기반 인터페이스를 통해 AWS 클라우드 리소스를 쉽게 관리할 수 있습니다.
aws.amazon.com
2. 로그인 후 S3 로 이동하자.
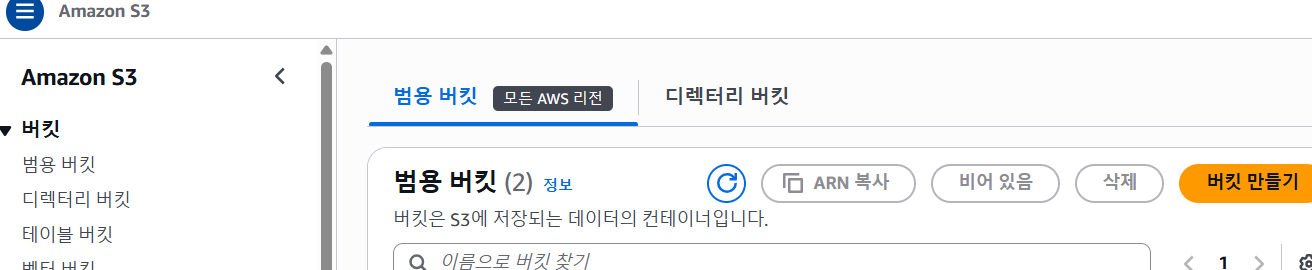
3. 버킷을 생성하자.
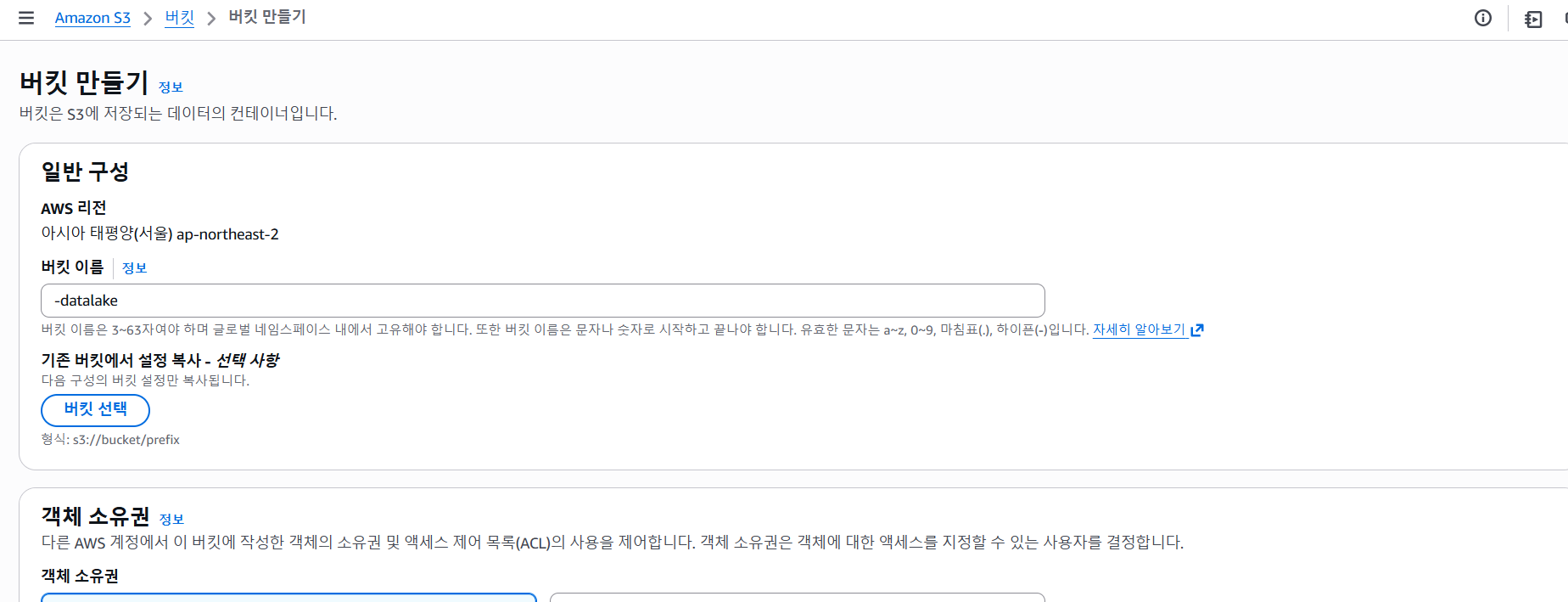
기본설정으로 "완료" 한다.
4. raw 데이터를 넣을 폴더와 model 폴더를 만들어주자.
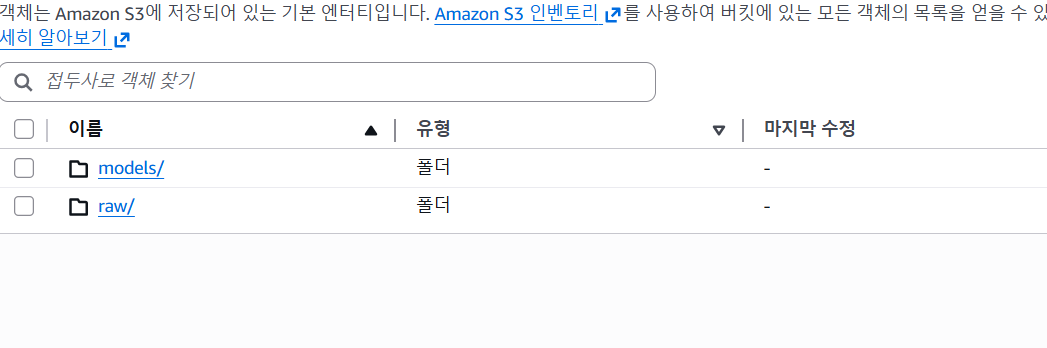
raw에는 말그대로 날것의(비정형화된) 데이터들을 위한 폴더며,
model 은 AI가 바로 판단할수 있는 데이터들로 정제하여 넣는 폴더이다.
✅ 에? 왜 Refined(정제) 도 해야하는거 아니야 ?? 왜 그 폴더는 없음?
지금은 poc 단계라 일단 정제 없이 (깨끗한 데이터므로) 비용절감을 위해 없앴다.
딱히 대시보드를 만들거나 해야하는게 아니므로 지금 Refined 과정은 생략했다. .(추후 기능에 따라 추가할수도 있다.)
5. Raw 폴더안에 날 것의 데이터를 업로드 해주자.
- 3년치 가계부 데이터를 .csv 형식으로 업로드 했다.
✔️ 데이터 분류해서 학습시키기.
1. Lambda로 이동하여 함수를 만들자.
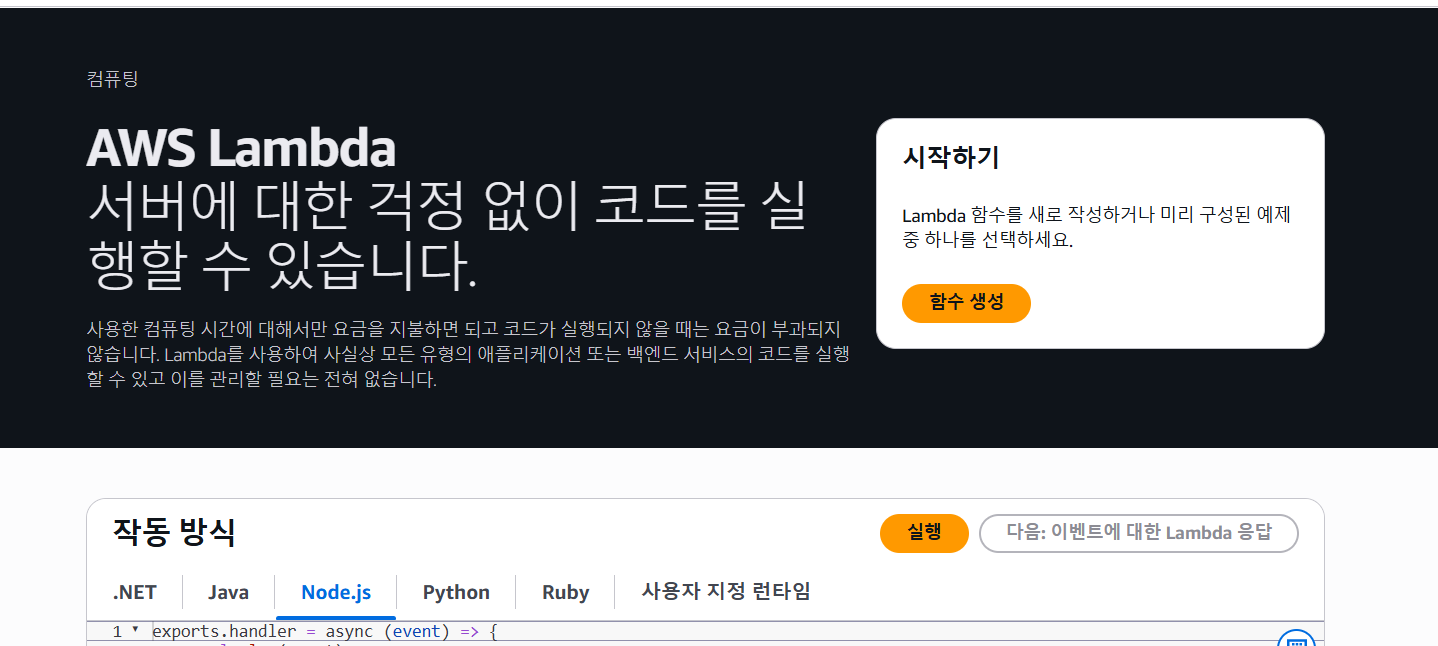

함수를 생성하면 위와같은 화면이 보인다.
👉 왜 Lambda 를 썼나?
EC2를 구동시켜서 하는 방법도 있으나 EC2의 경우엔 쓰든, 안쓰든 숨만쉬어도 월 2-3만원은 꼬박 내야 하는 돈이다.
개인 가계부의 데이터가 아주 작은 수준이고 가끔만 돌리면 되는 지라 Lambda를 이용하였다.
2. 권한 설정하기.
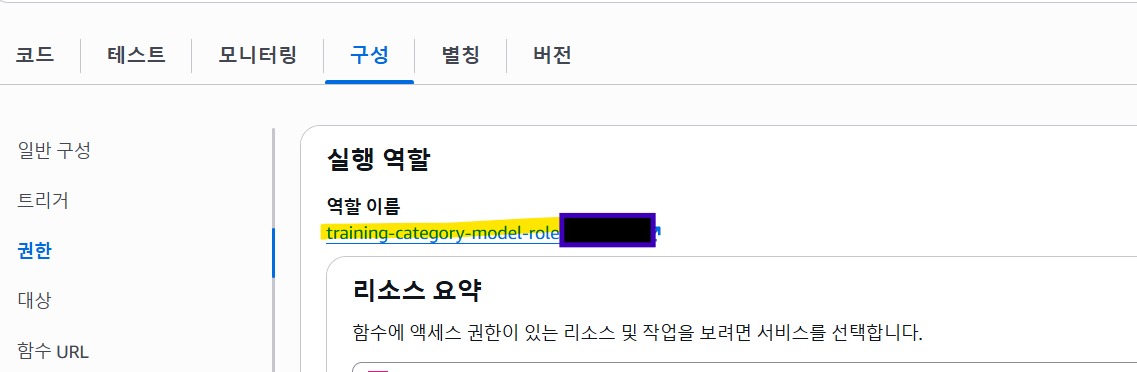
그럼 새 창이 뜨게 되는데 여기서 [권한 추가] -> [정책 연결] 을 클릭 후

AmazonS3FullAccess 을 검색하여 추가해준다.
(원래는 필요한 것만 줘야 하지만 난 POC 므로 걍 다 줘따.)
3. Pandas 레이어 추가하기



추가 하였다. 이제 코드를 넣어보자
4. 코드 넣기
다시 람다 함수 메뉴로 돌아와서 아래 코드쪽에 해당 코드를 추가한다.
import boto3
import pandas as pd
import os
import json
# =========================================================
# 버킷 및 폴더 파일이름
# =========================================================
BUCKET_NAME = "버킷이름"
INPUT_KEY = "분석할 파일경로/이름"
TARGET_KEY = "결과 파일경로/이름"
# =========================================================
def lambda_handler(event, context):
print("🚀 [Lambda] 학습 시작! (한글 깨짐 방지 모드)")
s3 = boto3.client('s3')
local_csv = "/tmp/input.csv"
# 1. 파일 다운로드
try:
print(f"📥 다운로드 중: {INPUT_KEY}")
s3.download_file(BUCKET_NAME, INPUT_KEY, local_csv)
except Exception as e:
return {"statusCode": 500, "body": f"❌ 다운로드 실패 (경로 확인): {str(e)}"}
# 2. Pandas로 분석 (한글 인코딩 자동 감지)
print("🧠 데이터 분석 중...")
try:
# 🔥 [핵심] UTF-8로 먼저 시도하고, 안 되면 CP949(엑셀한글)로 읽기
try:
df = pd.read_csv(local_csv, encoding='utf-8')
print("✅ 인코딩: UTF-8 성공")
except UnicodeDecodeError:
df = pd.read_csv(local_csv, encoding='cp949')
print("✅ 인코딩: CP949(엑셀한글) 성공")
# 컬럼명 공백 제거
df.columns = [c.strip() for c in df.columns]
# 끼리끼리 묶어서 개수 세기
grouped = df.groupby(['기본내용', '분류']).size().reset_index(name='cnt')
# 1등만 남기기
sorted_df = grouped.sort_values(by=['기본내용', 'cnt'], ascending=[True, False])
best_match = sorted_df.drop_duplicates(subset=['기본내용'], keep='first')
# 족보 만들기
category_map = dict(zip(best_match['기본내용'], best_match['분류']))
print(f"📊 결과: 총 {len(category_map)}개의 분류 규칙 생성됨.")
except Exception as e:
return {"statusCode": 500, "body": f"❌ 분석 에러: {str(e)}"}
# 3. 결과 업로드
try:
json_data = json.dumps(category_map, ensure_ascii=False) # 한글 안 깨지게 설정
s3.put_object(
Bucket=BUCKET_NAME,
Key=TARGET_KEY,
Body=json_data,
ContentType='application/json'
)
msg = "✅ [성공] 한글 데이터 완벽 처리 후 파일 생성 완료!"
print(msg)
return {"statusCode": 200, "body": msg}
except Exception as e:
return {"statusCode": 500, "body": f"❌ 업로드 실패: {str(e)}"}
해당 소스를 붙여넣은 뒤 "Deploy" 후 "Test" 를 해보자
REPORT RequestId: b00fe783-ca17-4fc5-8cb0-5df3d6a0c475 Duration: 3000.00 ms Billed Duration: 5610 ms Memory Size: 128 MB Max Memory
타임아웃과 램이 부족해서 일어난 오류다.

여기로 가서 메모리와 제한시간을 늘려주자.
메모리 -> 512MB
제한시간 -> 1분 00초
다시 Deploy 후 Test 하면 model/ 폴더안에 파일이 생성된걸 확인할 수 있다.
-끝-
'web > AI' 카테고리의 다른 글
| [AI] Sample App(Backend) 만들기.. (1) | 2026.02.05 |
|---|---|
| [DataLake] 파이프라인 고도화(1) (0) | 2026.01.25 |
| [AI] Spark(스파크) 이해하기 (1) | 2026.01.12 |
| [AI] MinIO(미니오)의 개념 (0) | 2026.01.09 |
| [AI] Hive Metastore (0) | 2026.01.08 |