Tool Calling 을 위해 RAG 구축이 필요하여 Qdrant 를 이용하려 한다.
일단 설치부터
[개발환경]
Window 11(64bit)
도커가 설치되어있다면 편하다
docker run -d -p 6333:6333 -p 6334:6334 --name qdrant qdrant/qdrant
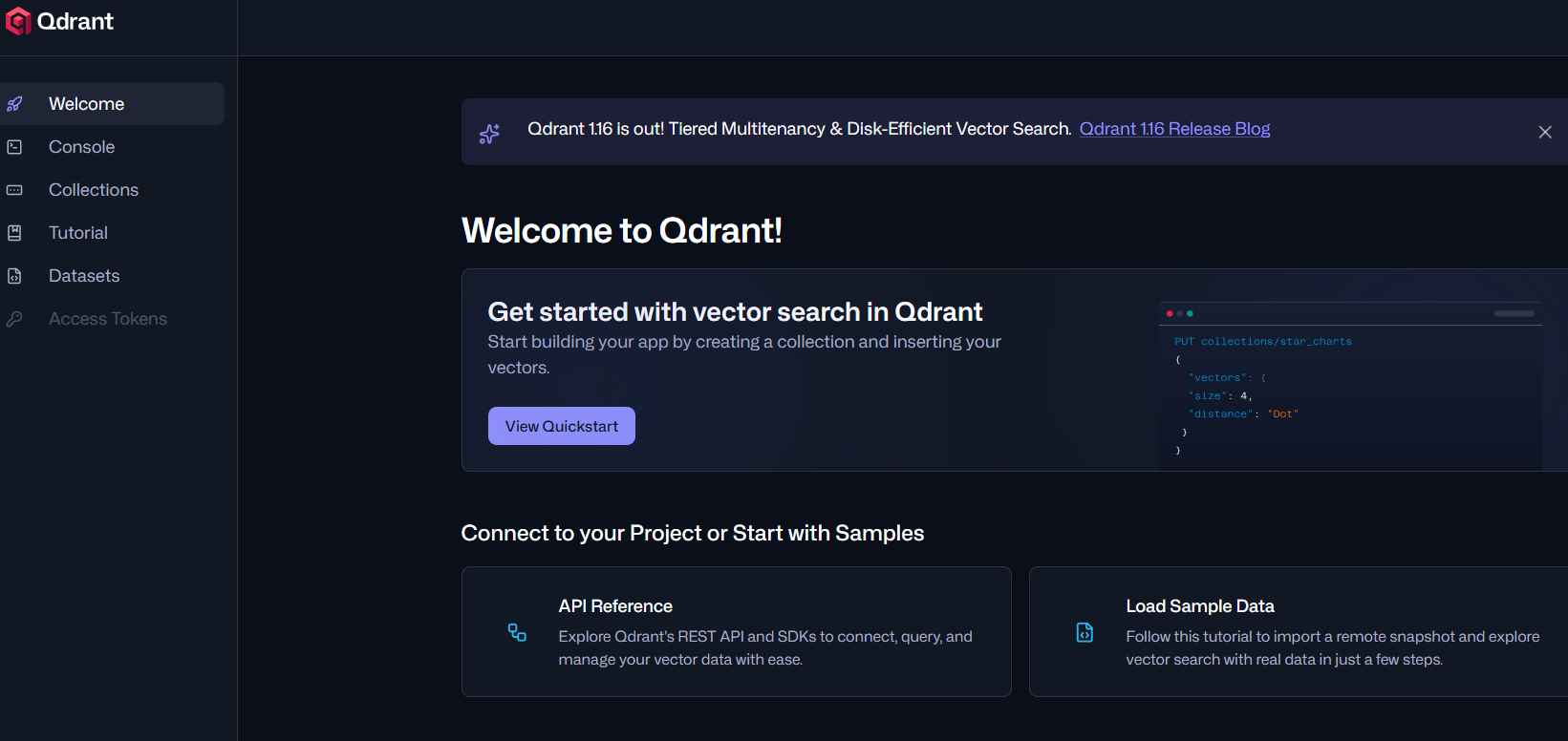
그런다음 http://localhost:6333/dashboard 로
접속해보면 아래와같은 화면이뜬다
✔️ 대시보드 화면
✔️임베딩모델 설치하기.
# 1. Qdrant 클라이언트
pip install qdrant-client
# 2. Sentence Transformers (임베딩 모델)
pip install sentence-transformers
# 3. PyTorch (자동으로 설치되지만 확인)
pip install torch
✔️데이터 Qdrant에 등록해보기
일단 나는 임시로 경로에 txt파일들을 몇개 넣고 실행했다.
# ========== 설정 ==========
DOCS_DIR = r"D:\RAG\proceedings"
QDRANT_HOST = "localhost"
QDRANT_PORT = 6333
COLLECTION_NAME = "documents"
EMBEDDING_MODEL = "sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2" # 한국어 지원
CHUNK_SIZE = 500 # 글자 단위
# ========== 1. 모델 로드 ==========
print("📦 임베딩 모델 로딩 중...")
model = SentenceTransformer(EMBEDDING_MODEL)
print(f"✅ 모델 로드 완료: {EMBEDDING_MODEL}")
# ========== 2. Qdrant 연결 ==========
print(f"\n🔌 Qdrant 연결 중... ({QDRANT_HOST}:{QDRANT_PORT})")
client = QdrantClient(host=QDRANT_HOST, port=QDRANT_PORT)
print("✅ Qdrant 연결 성공")
# ========== 3. 컬렉션 생성/확인 ==========
collections = client.get_collections().collections
collection_names = [col.name for col in collections]
if COLLECTION_NAME in collection_names:
print(f"\n⚠️ 컬렉션 '{COLLECTION_NAME}' 이미 존재 - 삭제 후 재생성")
client.delete_collection(COLLECTION_NAME)
print(f"📁 컬렉션 생성 중: {COLLECTION_NAME}")
client.create_collection(
collection_name=COLLECTION_NAME,
vectors_config=VectorParams(
size=384, # paraphrase-multilingual-MiniLM-L12-v2 차원
distance=Distance.COSINE
)
)
print("✅ 컬렉션 생성 완료")
# ========== 4. 문서 읽기 & 청크 분할 ==========
def read_txt_file(file_path: str) -> str:
"""텍스트 파일 읽기"""
with open(file_path, 'r', encoding='utf-8') as f:
return f.read()
def split_into_chunks(text: str, chunk_size: int = CHUNK_SIZE) -> List[str]:
"""텍스트를 청크로 분할"""
chunks = []
for i in range(0, len(text), chunk_size):
chunk = text[i:i + chunk_size]
if chunk.strip(): # 빈 청크 제외
chunks.append(chunk)
return chunks
print(f"\n📄 문서 읽기 시작: {DOCS_DIR}")
all_points = []
point_id = 0
for file_path in Path(DOCS_DIR).glob("*.txt"):
print(f"\n처리 중: {file_path.name}")
# 파일 읽기
content = read_txt_file(str(file_path))
print(f" 📏 파일 크기: {len(content)} 글자")
# 청크 분할
chunks = split_into_chunks(content, CHUNK_SIZE)
print(f" ✂️ 청크 개수: {len(chunks)}개")
# 임베딩 생성
print(f" 🧠 임베딩 생성 중...")
embeddings = model.encode(chunks, show_progress_bar=True)
# Point 생성
for i, (chunk, embedding) in enumerate(zip(chunks, embeddings)):
point = PointStruct(
id=point_id,
vector=embedding.tolist(),
payload={
"file_name": file_path.name,
"chunk_id": i,
"content": chunk,
"file_path": str(file_path)
}
)
all_points.append(point)
point_id += 1
print(f" ✅ {file_path.name} 완료 ({len(chunks)}개 청크)")
# ========== 5. Qdrant에 저장 ==========
print(f"\n💾 Qdrant에 저장 중... (총 {len(all_points)}개 포인트)")
client.upsert(
collection_name=COLLECTION_NAME,
points=all_points
)
print("✅ 저장 완료!")
저장한다음 대시보드로 가서 새로고침하면 Collection이 생성되어있고 확인해볼수 있다.

'web > AI' 카테고리의 다른 글
| [AI] Tool Calling (0) | 2025.12.17 |
|---|---|
| [AI] RAG 와 VectorDB (1) | 2025.12.17 |
| [AI] 챗봇만들기 프로젝트 (1) (0) | 2025.12.04 |
| [AI] MCP 프로토콜 (0) | 2025.12.03 |
| [AI] JIRA를 연동하여 주간업무 Agent 만들기(2) (0) | 2025.11.28 |